Featured Blog Posts

In this blog post you will learn how to create a Self Service Portal for Confluent Clusters using Backstage and Terraform

Learn how to create effective data products that drive business value and user adoption.

Confluent’s recent white paper, ‘The Data Streaming Organization: Driving Value & Competitive Advantage From Data Streaming,’ introduces a structured framework designed to help organizations navigate this transformative journey.
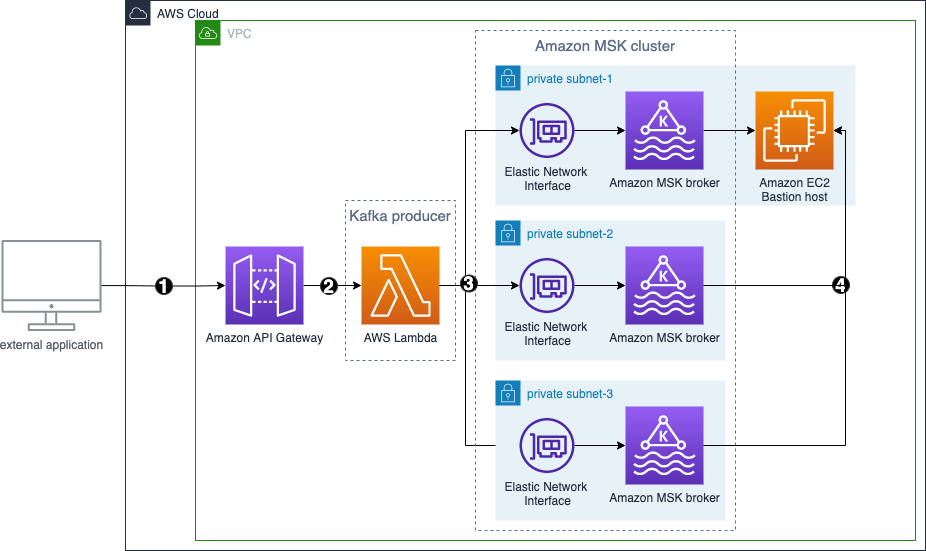
Learn how to build a serverless Apache Kafka producer using AWS Lambda and API Gateway to push real-time streaming data to Amazon MSK, with Java implementation examples and CDK deployment.
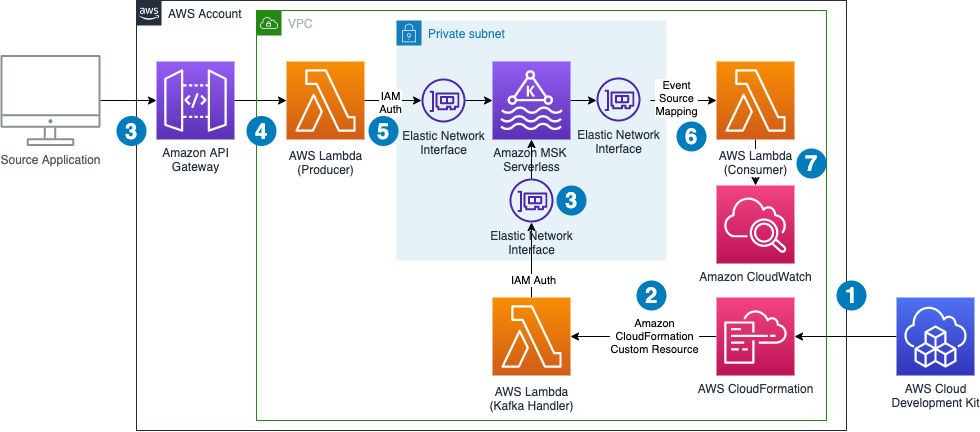
Learn how to build a serverless Apache Kafka producer using AWS Lambda and API Gateway to push real-time streaming data to Amazon MSK, with Java implementation examples and CDK deployment.